Org Log
I have long been an avid enthusiast of journaling. This has mostly been for the sheer sake of journaling. In other words: once written, never to be read.
At the same time I would like to use information about my past when making decisions for the future. When simply winging this inference on empirical data, I’m always worried that some warping could have altered my recollection of these experiences (in other words: a noisy communication channel) and thereby bias my inference mechanism unjustly. Think of recency bias, the peak-end rule or just plain nostalgia.
For that reason, I started using a dedicated, structured journal/diary/planner in addition to my very much purposefully chaotic default journaling. Said journal allows for explicit evaluation of a predefined set of dimensions on a daily basis. Moreover, it facilitates systematically revisiting past weeks and months. While I found this particular specimen to be very well made, it turned out to be, after a trial phase of two and a half years, impractical for my purposes.
I love the sensation of writing on egg-shell colored, soft, thick paper. It almost tickles my brain. Surprisingly, I even enjoy touching the exterior of a thin, soft-cover, leather notebook. (Ok I’ll stop it now.) Aside from these romantic tendencies towards the haptic aspects of physical writing, I also just like the concept of putting a thought on paper and putting the paper ‘away’. This is all fun and games when it comes to unstructured journaling; either a valve for what’s been damming up or just a catalyst for ripening thoughts. Yet, for retrospective evaluations, this is not great - for two reasons.
First, the dependency on the physical notebook is deterring. Sure; while one could in principle always take notes ’elsewhere’ while traveling and copy them to the ground truth notebook, it’s just very inconvenient. Just as it’s inconvenient to be forced to always carry your - likely not so thin - ‘retrospective evaluation notebook’. Second, evaluation is just so much easier when the underlying data is effortlessly parsable by software. In short: software beats hardware.
While still somewhat of a newcomer to it, I feel a lot of sympathy towards Org Mode. Org Mode is a ‘mode’ - think of it as a configuration - for Emacs. It outputs plain text files - just as with e.g. markdown or rst. One can edit these files with any text editor - yet when using Emacs’ Org Mode, the editing becomes particularly powerful.
I set out to define a rudimentary Org Mode file structure for three kinds of files:
- A template for a week - defining goals for it as well evaluating single days in retrospect.
- A template for the outlook on a month.
- A template for evaluating a month in retrospect.
These look as such:
Week template
* Focus
* Private goals
* Professional goals
* Monday
:PROPERTIES:
:Sleep: x
:Exercise: x
:Happiness: x
:Wellbeing: x
:Eating: x
:Stress: x
:Fasting: x
:END:
* Tuesday
:PROPERTIES:
:Sleep: x
:Exercise: x
:Happiness: x
:Wellbeing: x
:Eating: x
:Stress: x
:Fasting: x
:END:
* Wednesday
...
Pre-month template
* Goals and wishes
** Work
** Social
** Other
* Looking forward to
* Will be challenging
Post-month template
* This happened
* I'm thankful for
* I did well
* This was challenging
Note that the week template uses PROPERTIES. While the PROPERTIES are also just text, declaring them as such makes it handier to parse them later on. Furthermore, there is special support for these PROERTIES in Org Mode software that aren’t just text editors, e.g. mobile apps.
I wrote a script to apply that template to every week and month of the year. Hence $ ls ~/org/weeks/ returns the following:
1.org 10.org 11.org 12.org 13.org 14.org 15.org 16.org 17.org 18.org 19.org 2.org 20.org 21.org 22.org 23.org 24.org 25.org 26.org 27.org 28.org 29.org 3.org 30.org 31.org 32.org 33.org 34.org 35.org 36.org 37.org 38.org 39.org 4.org 40.org 41.org 42.org 43.org 44.org 45.org 46.org 47.org 48.org 49.org 5.org 50.org 51.org 52.org 6.org 7.org 8.org 9.org
and similarly $ ls ~/org/months/ returns:
1-jan_post.org 1-jan_pre.org 10-oct_post.org 10-oct_pre.org 11-nov_post.org 11-nov_pre.org 12-dec_post.org 12-dec_pre.org 2-feb_post.org 2-feb_pre.org 3-mar_post.org 3-mar_pre.org 4-apr_post.org 4-apr_pre.org 5-jun_post.org 5-may_post.org 5-may_pre.org 6-jul_post.org 6-jun_post.org 6-jun_pre.org 7-jul_post.org 7-jul_pre.org 8-aug_post.org 8-aug_pre.org 9-sep_post.org 9-sep_pre.org
Once the data is logged, a weekly file could look as follow (imagine the remaining days of the week - I got tired creating mock data - I figure I should hire an intern for my blog):
* Focus
Importance over urgency
* Private goals
** TODO Reread Bishop chapter on EM
** TODO File taxes
** DONE Write blog post on goals
CLOSED: [2022-02-13 Sun 10:00]
* Professional goals
** DONE Merge PR 1337
CLOSED: [2022-02-09 Wed 08:24]
** TODO Train model with new feature.
** TODO Prepare interview with Anne.
* Monday
:PROPERTIES:
:Sleep: 4
:Exercise: 4
:Happiness: 3
:Wellbeing: 4
:Eating: 3
:Stress: 2
:Fasting: 16.5
:END:
Had dreamt of sheep. Good meeting with Bob. Learned about @singledispatch.
Took a lot of time to stretch.
* Tuesday
...
In order to access - mostly reads, occasional writes - these org files in a convenient way via my mobile phone, I synchronize them via Dropbox. I would much rather push to a version-controlled repository but haven’t come across an app which can push/pull from github. I currently use orgzly and it looks as follows:
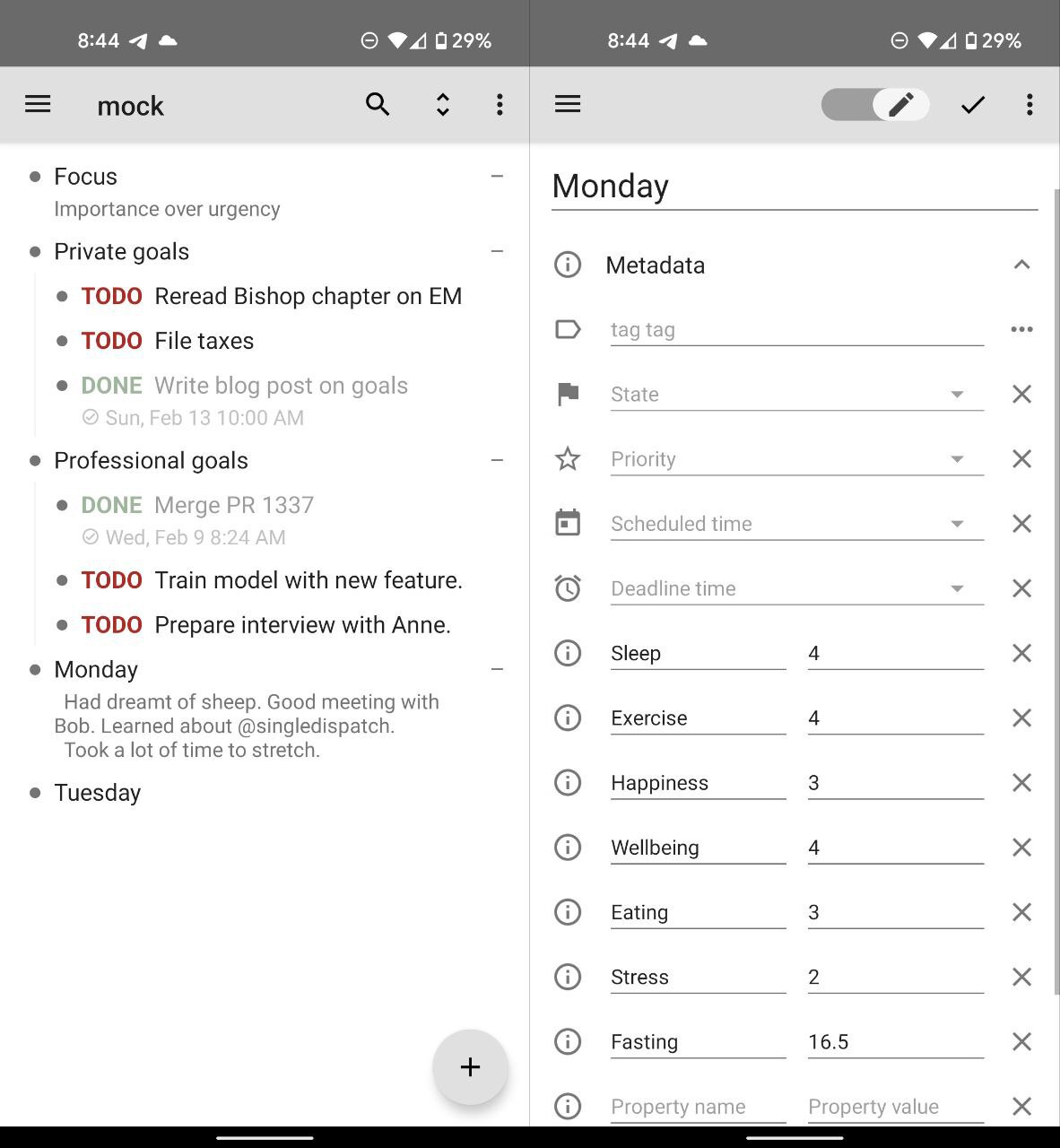
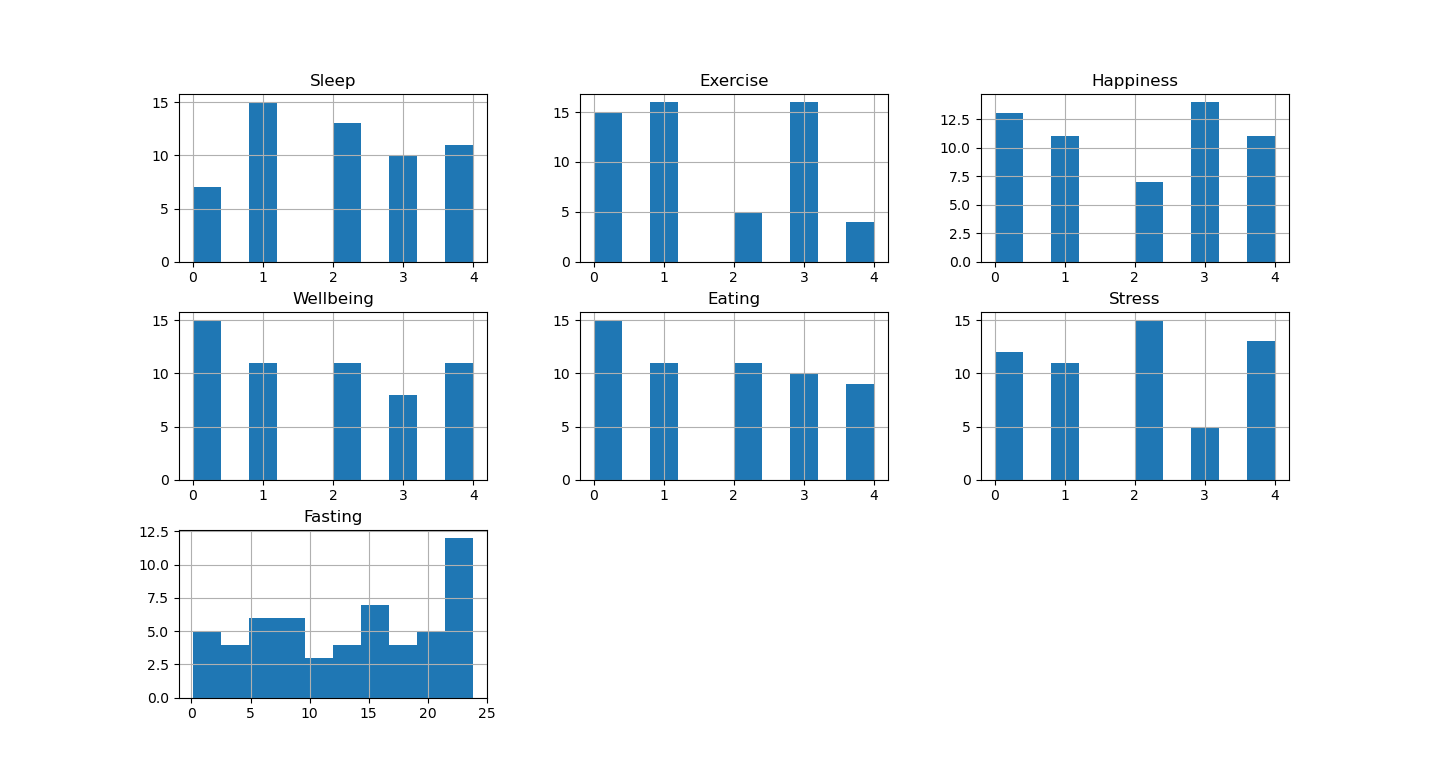
So much about the data entry/collection. I think I will think more about what to actually do with that data once I have more of it. So far, I’ve only parsed it orgparse and plotted histograms and trends. With noise as data this looks as follows:
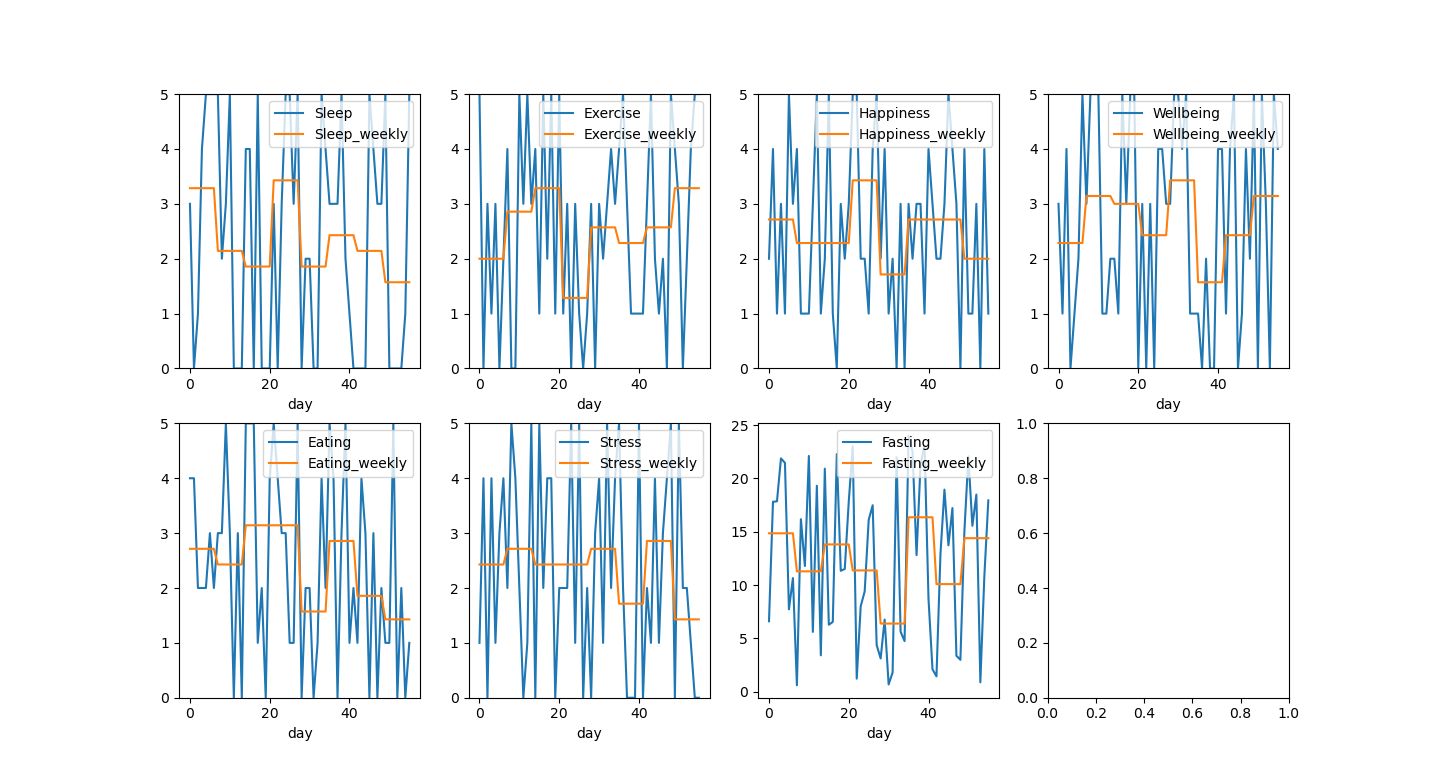
In the future it might be cool to automate a report generation/monitoring system.