Sort-of-art?
Recently, my friend Theo pointed me towards his amazing idea and execution of programming ‘paintings’ with the help of randomization.
I was fairly taken by the idea of programming with randomization to create sort-of-art. I kept thinking about cellular automata but reckoned that they often created outcomes that looked:
- overly structured in general
- busy, hard and cold in detail.
I figured that the latter could maybe be tackled by applying lots of smoothing, both on input and output image. The former seemed a bit harder to tackle as I’d need explicit rules/probabilities for something that would
- not be nothing
- not look overly structured
How to get ahold of such rules?
Approach
I came up with the idea of constructing rules based on neighboring colors. Given a colored central pixel, its neighboring pixels would be colored depending on the central pixel. The color of the neighbors could be determined by randomness: independently draw a color for each neighbor from a probability distribution over colors conditioning on the color of the central pixel.
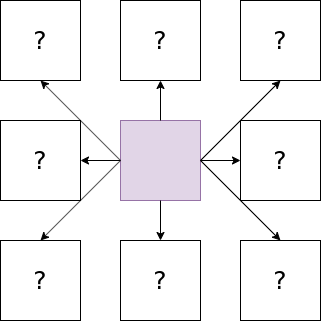
In this particular visualization one would need to look up the distribution conditioning on the own color being violet. Each arrow represents an independent draw from that distribution.
Yet, such a conditional distribution over colors needs to be defined. I didn’t feel sufficiently inspired to hard-code one myself. Hence the need to learn a conditional probability table of the sort: \(\Pr[color_{neighbor}| color_{own}]\). This could be inferred from a conditional histogram of an actual image.
Assuming the existence of only three colors, such tables could look the following way:
| \(color_{neighbor}\) | \(\Pr[color_{neighbor}| color_{own} = violet]\) |
|---|---|
| white | .15 |
| violet | .40 |
| rose | .45 |
| \(color_{neighbor}\) | \(\Pr[color_{neighbor}| color_{own} = white]\) |
|---|---|
| white | .20 |
| violet | .30 |
| rose | .50 |
| \(color_{neighbor}\) | \(\Pr[color_{neighbor}| color_{own} = rose]\) |
|---|---|
| violet | .18 |
| rose | .40 |
| white | .42 |
What histogram to use? The natural answer for an image processing project had to be Lena.
Given the nature of the ’neighboring’ relationship and the fact that
- the option space for ‘own colors’ and ’neighboring colors’ are identical,
- the neighboring color is only dependent on the original color cell, and no further context,
this relationship is naturally represented by a fully connected Markov chain.
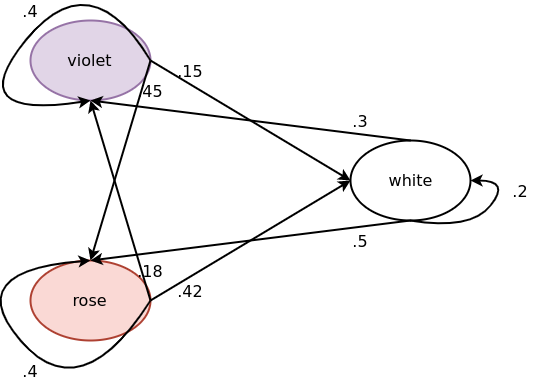
Put explicitly, the approach corresponds to the following:
1. Smoothen input image.
2. Learn conditional probabilities via conditional histogram on input image.
3. Create a blank output image of arbitrary resolution.
4. Pick a random pixel and color it according to some arbitrary distribution
over the set of possible colors.
5. Start a breadth-first exploration and color every neighbor by sampling
according to the conditional probability table of the current color.
6. Smoothen output image.
Note that the 5th step corresponds to starting a (respectively, many) random walk(s) on the Markov chain for every neighbor.
Also note that the 5th step is not parallelizable by default as it requires some mutual exclusivity on writes. Hence this could take a while for high resolution pictures without further concurrency enhancements.
I stumbled upon Jonathan Mackenzie’s github repo, which provided all of the necessary functionality.
Outcome
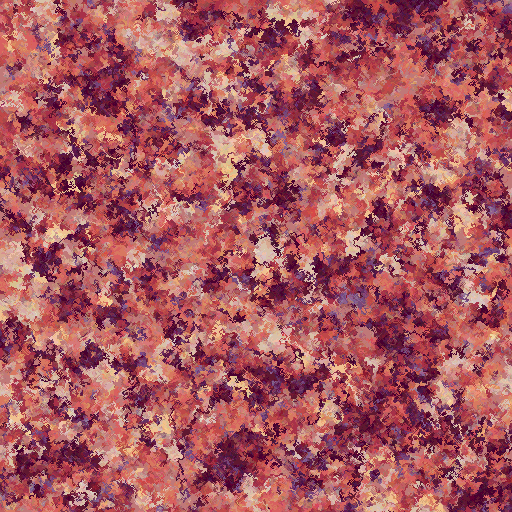
512x512 pixels

4000x5000 pixels, printed on roughly 33x42 cm